QuickStart
安装
pip install bddjango
接口编写
使用
BaseListView写一个接口作为案例,用少量代码实现了列表页的精确过滤、排序、去重、分页, 以及查看详情页等基本功能
建立模型
需要先建立django项目和一个名为
authors的app.
# models.py
from django.db import models
class AuthorInfo(models.Model):
# 第一个字段尽量不要放文件、图片等类型, 避免admin自动展示所有字段时出错
author = models.TextField(blank=True, null=True, verbose_name='作者姓名')
province = models.TextField(blank=True, null=True, verbose_name='省份')
num_of_thesis = models.IntegerField(blank=True, null=True, default=0, verbose_name='发文量')
class Meta:
verbose_name_plural = verbose_name = "作者信息表"
ordering = ('-num_of_thesis', 'id')
数据管理
在
admin.py中建立一个数据管理类, 然后创建或者右上角导入几个示例数据即可
# admin.py
from bddjango.adminclass import BaseAdmin
from django.contrib import admin
from . import models
@admin.register(models.AuthorInfo)
class AuthorInfo(BaseAdmin):
pass
-
数据导入导出按钮
将自动适配原生风格和
simpleui风格.(如下图)可用先
全部导出后, 用excel填写部分示例数据, 然后再导入数据.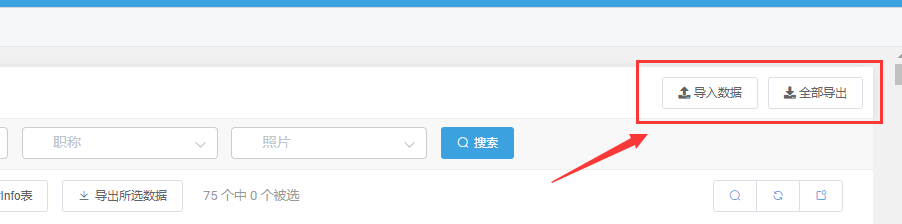
View编写
注意
ViewClass注释的风格, 用来自动生成wiki文档
# views.py
from . import models, serializers
from bddjango import BaseListView
from bddjango import CompleteModelView
# from bddjango.MultipleConditionSearch import AdvancedSearchView # 用这个代替BaseListView即可进行高级检索
class AuthorInfo(BaseListView):
"""
# 作者检索接口
- 用来对作者进行检索
- 也可以查看学者的省份分布
- `distinct_field_ls`设置为`province`
- `only_get_one_field`设置为`1`
GET /api/authors/AuthorInfo/ # 列表页
GET /api/authors/AuthorInfo/3/ # 详情页
"""
queryset = models.AuthorInfo
filter_fields = ['__all__'] # 开启所有字段为过滤字段
serializer_class = serializers.AuthorInfo # 也可用retrieve_serializer_class和list_serializer_class分别指定列表页和详情页的序列化器
# auto_generate_serializer_class = True # 自动生成序列化器, 可用base_fields指定具体返回哪些字段
# order_type_ls = ['num_of_thesis', 'id'] # 指定默认排序
# distinct_field_ls = ['province'] # 指定去重字段
Serializers编写
# serializers.py
from django.urls import path, re_path
from . import views
class AuthorInfo(serializers.ModelSerializer):
"""
不属于模型中的字段需要在这里做注释, 以生成wiki(注释风格兼容原版python风格)
- is_HuNan: 是否湖南省的作家
"""
is_HuNan = serializers.SerializerMethodField()
def get_is_HuNan(self, obj):
k_name = 'province'
ret = False
if hasattr(obj, k_name):
value = getattr(obj, k_name)
if value == "湖南":
ret = True
return ret
class Meta:
model = models.AuthorInfo
fields = '__all__'
路由设置
# urls.py
from django.urls import path, re_path
from . import views
app_name = "authors"
urlpatterns = [
# 详情页和列表页用同一个View来处理
re_path(r'^AuthorInfo($|/$|/(?P<pk>\w+)/$)', views.AuthorInfo.as_view()),
]
接口测试
- 获取所有作者
前端可指定页码、每页条目、排序字段
# 检索所有作者, 返回第一页, 每页10个, 按`num_of_thesis`字段倒序排序
GET {{url}}/authors/AuthorInfo/?p=1&page_size=10&order_type_ls=-num_of_thesis
- 获取省份
province=湖南省的作者
GET {{url}}/authors/AuthorInfo/?province=湖南省
- 获取发文量
num_of_thesis=1的作者
GET {{url}}/authors/AuthorInfo/?num_of_thesis=1
- 获取
pk=3的作者详情
GET {{url}}/authors/AuthorInfo/3/ # 注意斜杠
- 分析作者分布在哪些省份
按省份字段去重, 然后只返回指定的去重字段即可.
GET {{url}}/authors/AuthorInfo/?distinct_field_ls=province&only_get_distinct_field=1
- 使用
AdvancedSearchView可进行高级检索
根据Django的Q函数构造Post请求即可.
检索逻辑将按照离散数学命题逻辑的运算规则进行合并.
# 注意代码风格(post请求后的json格式数据), 以便自动生成wiki
POST {{url}}/authors/AuthorInfo/ # 高级检索示例
{
"目的": "检索[province]为[湖南 or 湖北], 且[num_of_thesis]大于等于[10]的作者, 并按[num_of_thesis]倒序排序",
"page_size": 10,
"p": 1,
"order_type_ls": ["-num_of_thesis"],
"Q_add_ls": [
{
"add_logic": "and",
"Q_ls": [
{
"add_logic": "and",
"search_field": "province",
"search_keywords": "湖南",
"accuracy": "1"
},
{
"add_logic": "or",
"search_field": "province",
"search_keywords": "湖北",
"accuracy": "1"
}
]
},
{
"add_logic": "and",
"Q_ls": [
{
"add_logic": "and",
"search_field": "num_of_thesis",
"search_keywords": "10",
"accuracy": "gte"
}
]
}
]
}
生成Wiki文档
自动生成wiki文档, 简化文档撰写操作.
配置urls.py
放到任意一个
urls中即可, 整个项目都通用.
# urls.py
...
from bddjango.autoWiki import AutoWiki # 可用path_of_jinja2_template自定义wiki文档风格
urlpatterns = [
re_path(r'^AutoWiki($|/$|/(?P<pk>\w+)/$)', cache_page(1)(AutoWiki.as_view()), name='AutoWiki'),
...,
]
调用接口
/api/authors/AutoWiki/?app_name=authors&view_class_name=AuthorInfo
参数说明
| 类型 | 参数名 | 说明 | 是否必填 |
|---|---|---|---|
| str | app_name | 指定app名 | 是 |
| str | view_class_name | 指定要生成文档的接口View名 | 否, 默认生成指定app下的全部view文档 |
| int | get_output_file | 是否直接下载wiki文件. 需要和view_class_name同时指定, 且建议win, mac平台选0, linux选1. | 否 |
返回示例
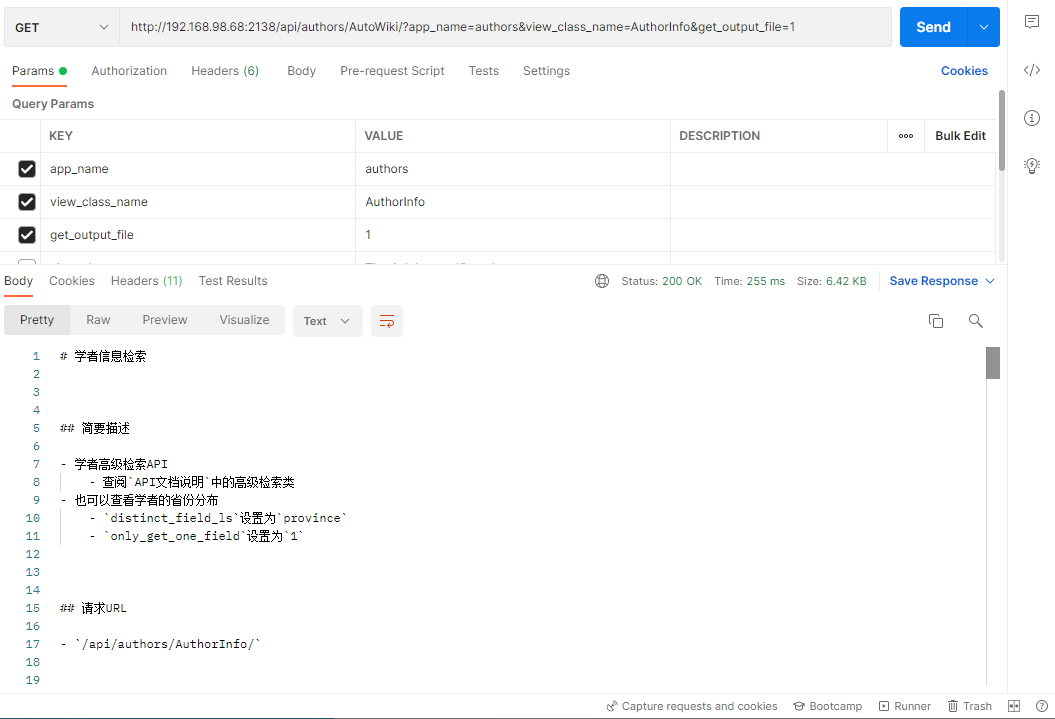
自定义风格
BaseListView继承了[ListModelMixin, RetrieveModelMixin, GenericAPIView]类, 所以可用类似方法来自定义接口风格.- 这里使用
conf.py来记录配置好的项目接口自定义风格类.
# conf.py
from bddjango import Pagination, JSONRenderer # 自定义默认分页器和返回格式
class MyPagination(Pagination):
page_size = 30
page_size_query_param = 'page_size'
page_query_param = 'p'
class CodeMsgResultJsonRenderer(JSONRenderer):
"""
保证项目代码风格, 统一返回数据的格式
"""
def render(self, data, accepted_media_type=None, renderer_context=None):
assert 'status' in data and 'result' in data, f'错误! {str(data)}'
data['code'] = data.pop('status')
data['data'] = data.pop('result')
ret = super().render(data, accepted_media_type, renderer_context)
return ret
class MyBaseListView(BaseListView):
pagination_class = MyPagination
renderer_classes = [CodeMsgResultJsonRenderer]
auto_generate_serializer_class = True
filter_fields = ['__all__']
class MyAdvancedSearchView(AdvancedSearchView):
pagination_class = MyPagination
renderer_classes = [CodeMsgResultJsonRenderer]
auto_generate_serializer_class = True
filter_fields = ['__all__']